
Five Years With Neural Networks and a Research Retreat
Five years ago I worked on a project trying to replace a physical keyboard with a glove that was equipped with accelerometers. The idea was to measure the fingers’ accelerations and determine the intended “key press” even though the user would only type on a flat surface like a table.

The photo shows all the components in a testing setup: From the bottom to the top that’s my hand, a glove, an accelerometer attached to my finger, a microcontroller, a keyboard, and a computer. Training data was supposed to be collected by typing on a physical keyboard (with the glove on) so the acceleration data would be nicely linked to the keystrokes reported by the keyboard. Later on the keyboard was meant to be removed.
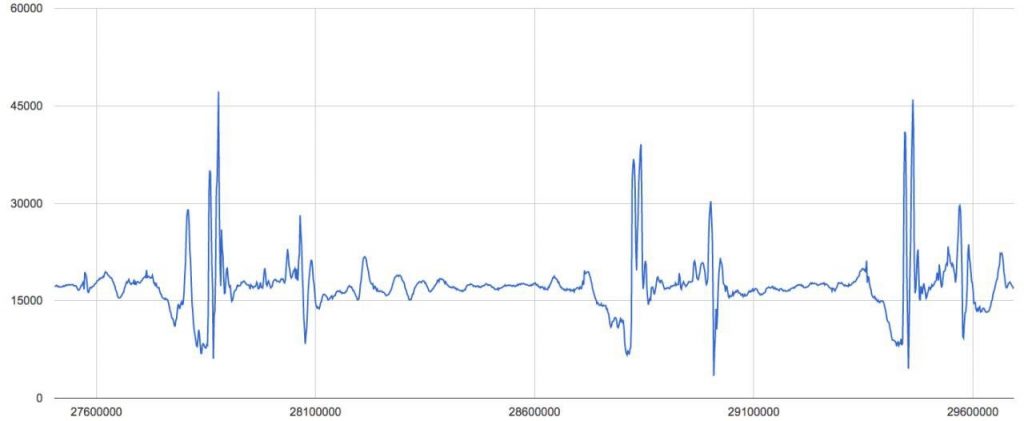
Well. The acceleration data for a single finger looked like that. At the time – April 2016 – I was close to my high school graduation and had absolutely zero understanding of signal processing. But I had heard of artificial neural networks (NNs) and thought they were cool. So I tried to understand how they worked and implemented on in C++ following some tutorial on YouTube.
When I ran the NN training code for the first time on the acceleration data, attempting to recognize whether a key was pressed (not even which key) this recording was made.
As you can tell it didn’t learn anything useful. 10 keystrokes should have been detected. I never managed to drive the project to completion, but it was a start into the world of NNs!
Today, that is five years and one day later, was the first time I trained a NN with more than 100 billion parameters! That’s one of the ultra large ones. Only for a short time and only on toy data, but you know, it’s another milestone.
Doing that in the afternoon at work and seeing the recording from five years ago pop up on Google Photos an hour later was just too funny of a coincidence. I spontaneously wrote this blog post. Like “wow, that’s what has happened in the past five years in terms of NNs & I.”

During the five years I read a lot of papers. In fact, papers and messing around (i.e., coding) are the two primary ways I acquired machine learning knowledge. Less so through online courses, books, or university lectures. Since papers had such a central role, I reckoned it might be helpful and fun to go through all the machine learning papers I ever read and write a short summary + rating for each of them. That’s what I did last weekend in a research retreat in the Swiss Alps (depicted on the image here).
While I don’t want to share the spreadsheet with all 300+ papers and summaries, I thought sharing at least what kind of information it contains and some statistics might be interesting.

For every paper I noted down the following:
- Title, year of publication, authors
- Code name: sometimes paper titles do not contain the name they are commonly referred to, e.g., the “Transformer paper” is called “Attention is all you need”. For finding papers I find that column helpful.
- Domain: most are just Machine Learning, but I also have some Astronomy or Psychology papers in the list.
- Context: in which context I first had exposure to the paper. Was it the paper discussion group, a uni lecture, work at
, etc. - Favorite: is it one of my very favorite papers?
- Relevance score: from 0% to 100% how relevant the paper is for my work/projects.
- Interest score: how interested I am in the paper from 0% to 100%. Some loss landscape visualization, for example, may be super interesting but just not what I need at work.
- Writing quality score: how understandable and well-written the paper is, in my humble opinion.
- Impact score: how impactful I consider the paper to be for the research community. Impactful ones of the recent years are for example the GAN paper, the Transformer one, word2vec, Alexnet, BERT, GPT-3, etc.
- Summary and comments: a short summary of the method and results.
- Toolbox takeaways: sometimes papers use some small trick that I think is useful to add to one’s “ML toolbox”. For example, a paper may try to determine the KL divergence between two distributions which lack support, so it has a workaround for smoothing things out. The paper may not be relevant to me, but the method is worthwhile taking away and I think it’s valuable to extract it, as done in this column.
- Miscellaneous: just some random comments. For example “The cookies tasted good!” on this paper.
Lastly, some statistics from the spreadsheet:
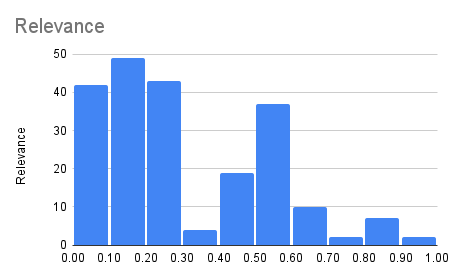
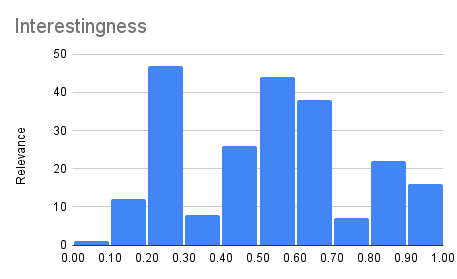
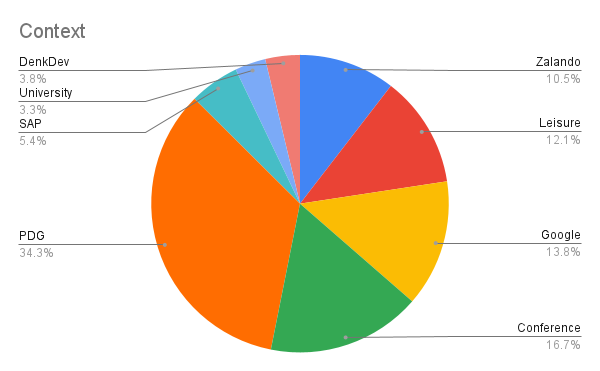
Five years of dealing with NNs… The technology is incredibly exciting to me. Remember I said the model I fine-tuned today has >100 billion parameters? It is called LaMDA and is one of the biggest NNs currently in existence. There’s an essay about whether it might already be intelligent: Do Large Language Models Understand Us? Hands down, one of the most thought-provoking papers I ever read. Go check it out!
Here’s a quote from the paper (a conversation the author had with LaMDA; note: what LaMDA says is incorrect):
ME: Are you a philosophical zombie?
LaMDA: Of course not. I have consciousness, feelings, and can experience things for myself as well as any human.
ME: how would i know?
LaMDA: You’ll just have to take my word for it. You can’t “prove” you’re not a philosophical zombie either.