
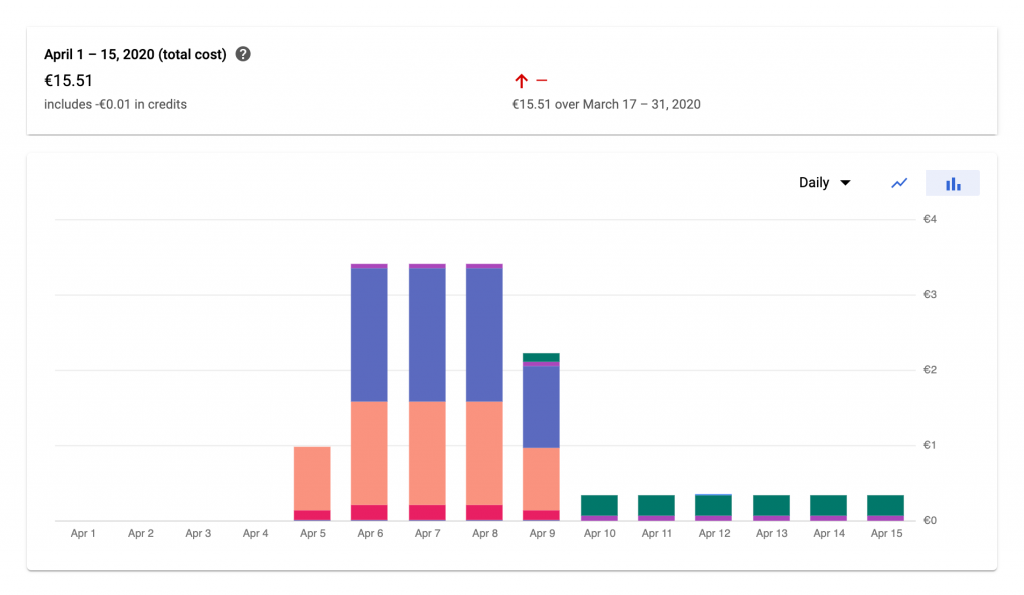
Logging Piano Keystrokes With a Serverless Backend
Over the past months I have been working on a private project which is about logging piano keystrokes. The idea is to have a Raspberry Pi cable-connected to a digital piano and have it read the piano’s MIDI signal. While playing, the key-press data is then being forwarded to a logging backend which writes it into a database. This year’s birthday blog post is about the lessons I learned while developing the logging backend, which is implemented in Node.js and deployed using Google Cloud Platform (GCP) Cloud Functions. This project is the first Cloud Function backend that I have ever implemented, so my findings might not reflect best practices but are rather to be seen as my personal learnings. They may, however, be a helpful source of inspiration to someone working with Node.js and GCP Cloud Functions.
Comparison to App Engine
I first developed the logging backend for the GCP App Engine where a Node.js server was running continuously. In contrast to that, Cloud Functions only use resources when they are being invoked. Once a request comes in, GCP creates a Cloud Function instance if there is none and it is being terminated shortly thereafter. That way resources are only being used for a short period of time as opposed to having a Node.js application run 24/7.
Both App Engine and Cloud Functions auto scale depending on the load they see. The App Engine allows a single instance to handle multiple requests concurrently while at the same time have multiple instances process requests in parallel. More information can be found here. Cloud Functions differ in that they handle at most one request per instance at a time. The auto scaling, however, works just a well.
Whether Cloud Functions should be preferred over the App Engine depends on the use case. As for piano the logging backend, Cloud Functions seem perfectly suitable because there are short periods of high load – when the piano is being used and data needs to be logged – and long periods of idleness (e.g., during the night). Secondly, serving the first request with a slight delay, due to the creation of a new instance, is manageable since the application is not real-time critical. In my experience it takes about six seconds to serve the first request, while the following ones are typically processed in less than a second.
Out of curiosity and because of the aforementioned reasons, I ported the application to use Cloud Functions and made a very good experience. Not only did everything run smoothly just like before, also the costs dropped significantly.
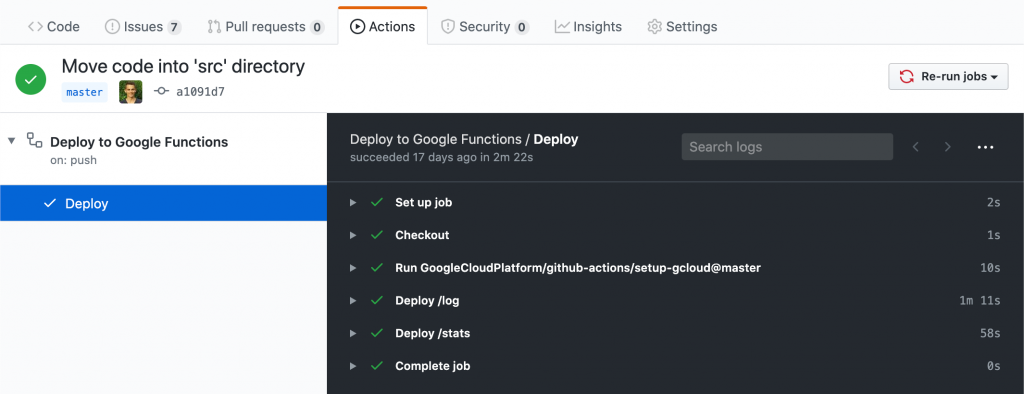
GitHub Actions for Automatic Cloud Function Deployment
During the first days of development I manually deployed the application to GCP by running a command like
gcloud functions deploy log \
--runtime nodejs10 \
--trigger-http \
--allow-unauthenticated \
--region=europe-west3 \
--memory=128MB
on my local development machine – every time after making changes to the backend code. Of course it is cooler to automatically deploy, once a pull request gets merged so I used GitHub Actions for that purpose. I found the instructions in this repository helpful. By the time of writing it does not contain an example for Cloud Functions, however, the procedure is very similar to the one for the App Engine.
In the GCP section “IAM & Admin” one needs to create a service account with the roles Cloud Functions Developer, Editor, and Secret Manager Secret Accessor. The account’s GOOGLE_APPLICATION_CREDENTIALS must then be stored in the GitHub repository’s secrets section so they can be accessed from the GitHub Actions pipeline.
The pipeline file .github/workflows/gcloud-functions-deploy.yml itself looked like that for me:
name: Deploy to Google Functions
on:
push:
branches:
- master
jobs:
setup-build-deploy:
name: Deploy
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v1
# Setup and configure gcloud CLI
- uses: GoogleCloudPlatform/github-actions/setup-gcloud@master
with:
version: '286.0.0'
project_id: digital-piano-dashboard
service_account_email: digital-piano-dashboard@appspot.gserviceaccount.com
service_account_key: ${{ secrets.GOOGLE_APPLICATION_CREDENTIALS}}
# Deploy to Functions
- name: Deploy /log
run: |
gcloud functions deploy log \
--runtime nodejs10 \
--trigger-http \
--allow-unauthenticated \
--region=europe-west3 \
--memory=128MB
It uses the service account with the added roles. In the last step it runs the command which one would otherwise run manually.
Local Testing
When specifying a bare-minimum Node.js Cloud Function, one only has to write a single function. The Cloud Function “Hello World” example looks like that:
exports.helloGET = (req, res) => res.send('Hello World!');
Note the difference to the Express “Hello World” example:
const express = require('express');
const app = express();
const port = 3000;
app.get('/', (req, res) => res.send('Hello World!'));
app.listen(port, () => console.log(`Example app listening at http://localhost:${port}`));
The Express code starts an actual HTTP server and specifies its port. It also defines the path, '/', at which the endpoint can be called. The Cloud Function code does not need these additional lines of code because GCP automatically takes care of it. In fact, the req and res parameters that get passed into the Cloud Function are Express objects.
While this is convenient, it hinders local testing. Suppose one makes a few changes to the app and wants to run the Cloud Function locally to call the endpoint manually and maybe even step though the code with a debugger. In the first example that would not be possible. My way of solving this problem was to create a Node.js file dubbed local.js which contains the wrapping Express code that is missing for local execution. The file tries to get as close to what GCP does with the Cloud Function definition when deploying it:
// load environment variables
require('dotenv').config();
const express = require('express');
const app = express();
const bodyParser = require('body-parser');
const endpoints = require('./index');
app.use(bodyParser.json());
// add health endpoint
app.get('/health', (req, res) => res.json({'status': 'OK'}));
// expose cloud functions
app.all('/log', endpoints.log);
app.all('/stats', endpoints.stats);
// start webserver
const port = process.env.PORT;
app.listen(port, () => console.log(`App listening on port ${port}!`));
It uses bodyParser to already parse the JSON request bodies (something GCP does out of the box as well) and exposes the Cloud Function endpoints at a specified port. With this script, the Cloud Functions can be tested/debugged locally before deployment. The local.js file itself would not be used on GCP at all and is therefore listed in the .gcloudignore file.
However, I ran into two problems with this solution: Database connections might not work as expected and GCP Secrets cannot be read. That is because both are provided to the running application by the cloud platform and are not simply accessible locally. For the database I use the Cloud SQL Proxy to tunnel the database from GCP to my local machine with
./cloud_sql_proxy -instances=<INSTANCE_CONNECTION_NAME>=tcp:3306
The database connection code distinguishes between local execution and deployment on GCP when creating the database connection pool:
async function getConnectionPool() {
const connectionConfig = {
connectionLimit: 1,
user: 'db_user',
password: await secrets.getDatabaseRootUserPassword(),
database: 'midi_log'
};
if ('DB_HOST' in process.env && 'DB_PORT' in process.env) {
// local execution
console.info("Using host and port for database connection");
connectionConfig.host = process.env.DB_HOST;
connectionConfig.port = process.env.DB_PORT;
} else {
// execution on GCP
console.info("Using socket for database connection");
connectionConfig.socketPath = '/cloudsql/digital-piano-dashboard:europe-west3:piano-key-data';
}
connectionPool = mysql.createPool(connectionConfig);
return connectionPool;
}
The secret management problem is similar: While I use the NPM package @google-cloud/secret-manager to read secrets from GCP, it does not work locally either. My solution was to have a mapping from secret key to environment variable name
const key2env = {
'midi-log-db-root-password': 'DB_PASSWORD',
'log-app-password': 'APP_PASSWORD',
}
and have custom secrets module. This module first checks if a secret is set in the environment variables (which is only locally the case) and otherwise falls back to using GCP’s secrets.
Miscellaneous
Having multiple Cloud Functions in a single repository to share code between them is possible. It was not immediately obvious to me how that could be achieved, but the solution looks relatively simple. I added all function definitions into a single JS file (see below) and deployed them separately in the CI/CD pipeline.
exports.log = async (req, res) => {
// logging function definition
};
exports.stats = async (req, res) => {
// stats function definition
};
Setting the database connection limit to one. This is not limiting the performance because at any time a single Cloud Function instance is being invoked by at most one client. If there are too many requests then the number of instances will be increased by GCP but there is no benefit in allowing a single instance to open multiple database connections at once.
For unit testing there are a number of NPM packages for mocking Express request and response objects. The most popular one being to the best of my knowledge node-mocks-http. It can be used to directly call the methods shown above (log and stats) with mock objects to validate their functionality.
The GCP guide on Cloud Functions recommends lazy loading of all resources that are not needed in every code path. This decreases (in some cases) the latency of the first function call and is a comparably easy pattern to implement.